Gopathi Suresh KumarConversational AI model (ChatGPT)In continuation of previous ChatGPT Uses2 min read·Apr 13, 2023----
Gopathi Suresh KumarUses of ChatGPTChatGPT is a large language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. It is designed…3 min read·Apr 11, 2023----
Gopathi Suresh KumarTicTacToe Game App with Python Code“Hey everyone, I’m excited to share my latest project with you — a Tic-Tac-Toe game with a graphical user interface! 🎮🖥️2 min read·Apr 8, 2023----
Gopathi Suresh KumarIntroduction to NLP — Package Creation for Pre ProcessingNatural Language Processing (NLP)4 min read·Feb 20, 2021----
Gopathi Suresh Kumarఆర్టిఫిషియల్ ఇంటెలిజెన్స్ (AI)My first Article in Telugu Language1 min read·Feb 19, 2021----
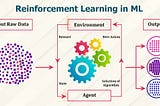
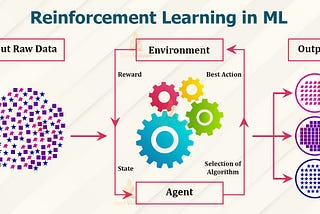
Gopathi Suresh Kumar3 ways to get into reinforcement learningReinforcement3 min read·Feb 19, 2021----
Gopathi Suresh KumarData Science and ML interview questionsQuestion 1) How to choose the value of the regularisation parameter (λ)?46 min read·Jul 27, 2020----
Gopathi Suresh KumarLinear Regression and General ML QuestionsQuestion 1) What is linear regression?4 min read·Jul 27, 2020----